An OCR API that returns data you can verify
One REST call returns structured JSON where every field carries a bounding box and a match score. Bearer auth, built-in templates, async jobs, signed webhooks.
Most OCR APIs hand you a wall of text and a confidence number for the whole page. You still have to find the invoice total, parse it, and hope it landed in the right place. The OCR API in space-ocr does the structuring for you: one POST with an image and a template, and you get back typed fields as JSON.
The part that matters for production is what rides along with each value. Every field comes back with the exact box on the page it was read from, the four corners of that box, and a match score. So your pipeline doesn't have to trust a model's word — it can check each value against where it actually sits on the document.
A real response you can inspect
Hover any field below — the box on the invoice is where that value was read. This is a real parsed result: the billing name ソジュハンザン海物語様, the amount due ¥84,263, the total ¥46,752, each line item, all returned with their own box and a match score. Nothing here is mocked.
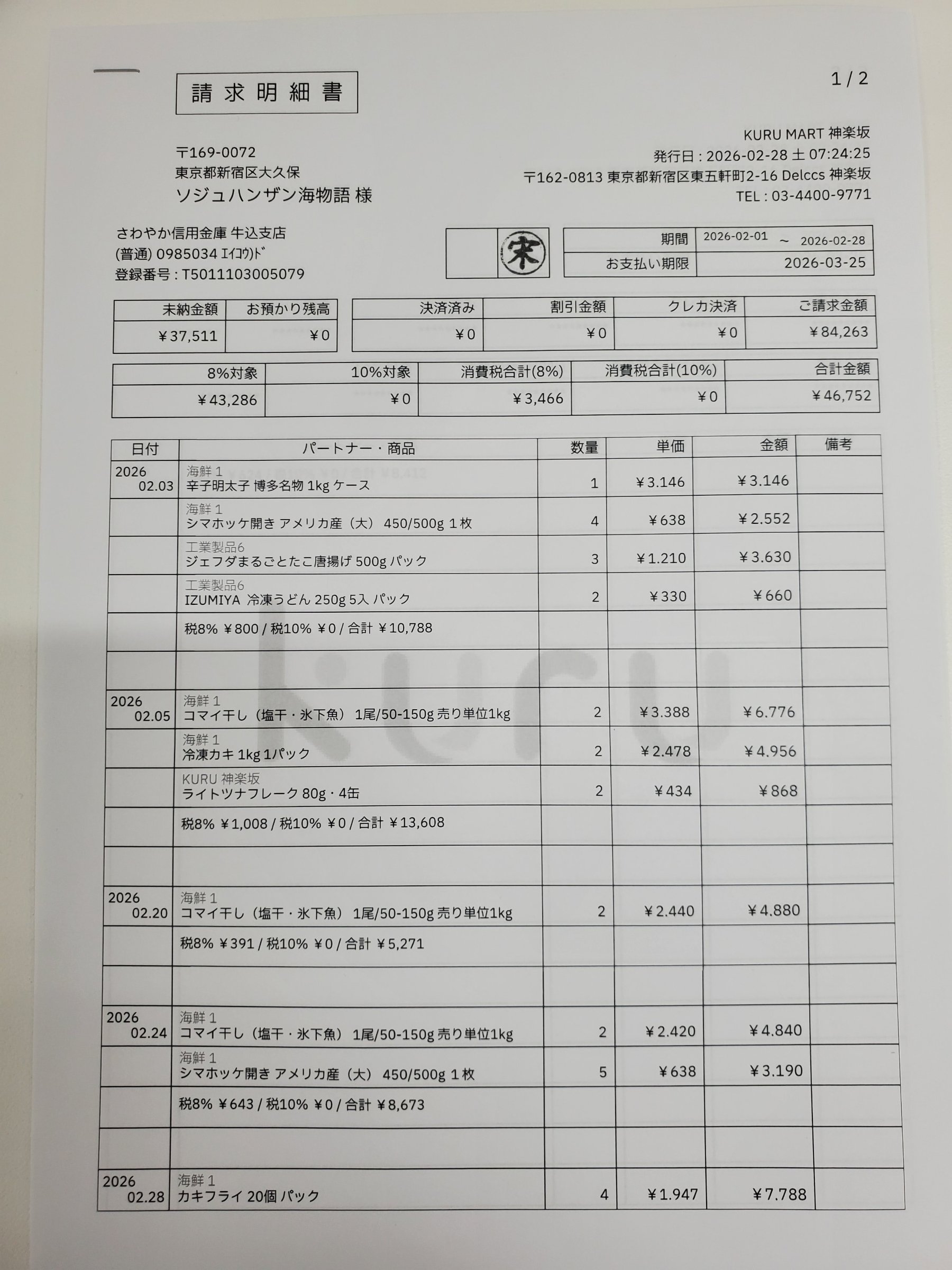
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
How the OCR API works in space-ocr
Authenticate with a Bearer token — your key is prefixed spocr_ — against the base URL https://api.space-ocr.com. Send one raster image to POST /ocr/fields as a URL or base64 (the public API takes images — JPEG, PNG, GIF, BMP, TIFF, WebP — so for a PDF you send page images). Pass a built-in templateId or your own fields, and you get back { status: 'success', data: {...} } with a value, bbox, vertices, and match_ratio per field.
The coordinates aren't invented by the model. The LLM returns each value plus the word-token ids it used; a character matcher then aligns that value against the symbols Google Vision actually detected on the page and scores the coverage as the match_ratio. A score of 0.85 or higher is a confident match, and 1.0 means every character was located. Every response also carries an X-Request-Id header, and errors come back as { error: { code, message, requestId } }.
curl -s https://api.space-ocr.com/ocr/fields \
-H "Authorization: Bearer $SPACE_OCR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice"
}'import os, requests
resp = requests.post(
"https://api.space-ocr.com/ocr/fields",
headers={"Authorization": f"Bearer {os.environ['SPACE_OCR_API_KEY']}"},
json={
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice",
},
timeout=60,
)
resp.raise_for_status()
for name, field in resp.json()["data"].items():
print(name, field["value"], field["bbox"], field["match_ratio"])How to call the OCR API
- Get an API keySign in and create a key — it is prefixed spocr_. Send it as Authorization: Bearer <key> on every request to https://api.space-ocr.com.
- Send an imagePOST /ocr/fields with image (a URL or pure base64) and imageType. For a PDF, send the page images — the API takes raster formats (JPEG, PNG, GIF, BMP, TIFF, WebP).
- Pick a template or fieldsPass a built-in templateId like 'invoice' or 'receipt', or supply your own fields — including an array field with children for line-item tables.
- Read the structured resultYou get { status: 'success', data: {...} } where each value carries its bbox, vertices, match_ratio, and bbox_source. Threshold on match_ratio to flag anything below 0.85.
- Scale out and queryQueue many images with POST /upload (job per file, signed webhooks or GET /jobs/{jobId}), then read a stored sheet with GET /view using where, sort, and select — no re-OCR, no extra charge.
Simple, predictable pricing
Pay $0.05 per image (¥10 / ₩100), with a free tier of 100 scans a month and no credit card. Reading a stored sheet back with GET /view doesn't re-OCR and isn't charged. Flat plans add monthly scans, more sheets, and storage.
How do I authenticate with the OCR API?
What does the OCR API return for each field?
Can the OCR API read a PDF?
Does the OCR API handle large or batch jobs?
Are there rate limits and error codes?
How much does the OCR API cost?
Ship OCR that returns checkable data
Free tier — 100 scans a month, no credit card. Every field comes back with its box and a match score.