用于提取发票数据的 API
space-ocr 发票数据提取 API 开发者指南:用 curl 与 Python 调用 POST /ocr/fields、内置发票模板、自定义字段,以及可核验的边界框(bounding box)。
从一张发票里抽取结构化数据——供应商、发票号、日期、行项目金额、税额——是最常见的文档自动化需求之一,也是手写最折腾的一类。靠正则去匹配 OCR 文本,供应商一改版式就全盘失效;模板匹配类工具又要你给每个供应商手动框选区域。你真正想要的,是一个能读懂任意版式、返回干净的强类型字段,并且——这点至关重要——能告诉你每个值在页面上的来源位置、从而让结果值得信任的发票数据提取 API。
最后这点才是关键。一个只丢回 total: 2,045、却不带任何溯源信息的发票提取接口,放进应付账款(accounts payable)流程里就是个隐患。本指南会带你走一遍 space-ocr 的 POST /ocr/fields 接口:一次同步调用,传入一张发票图片,套用内置的 invoice 模板(或你自己的字段结构),即可返回每个值及其经过核验的边界框(bounding box)。
先看输出,再写代码
下面是一张真实解析后的收据。把鼠标悬停在任意字段上,图片上对应的框就会高亮——那个框正是该值被读取出来的位置,而每个字段还各自带着自己的匹配率(match ratio)。发票的处理方式完全一致:你提取的每个字段,都会落回它原本来源的像素上。
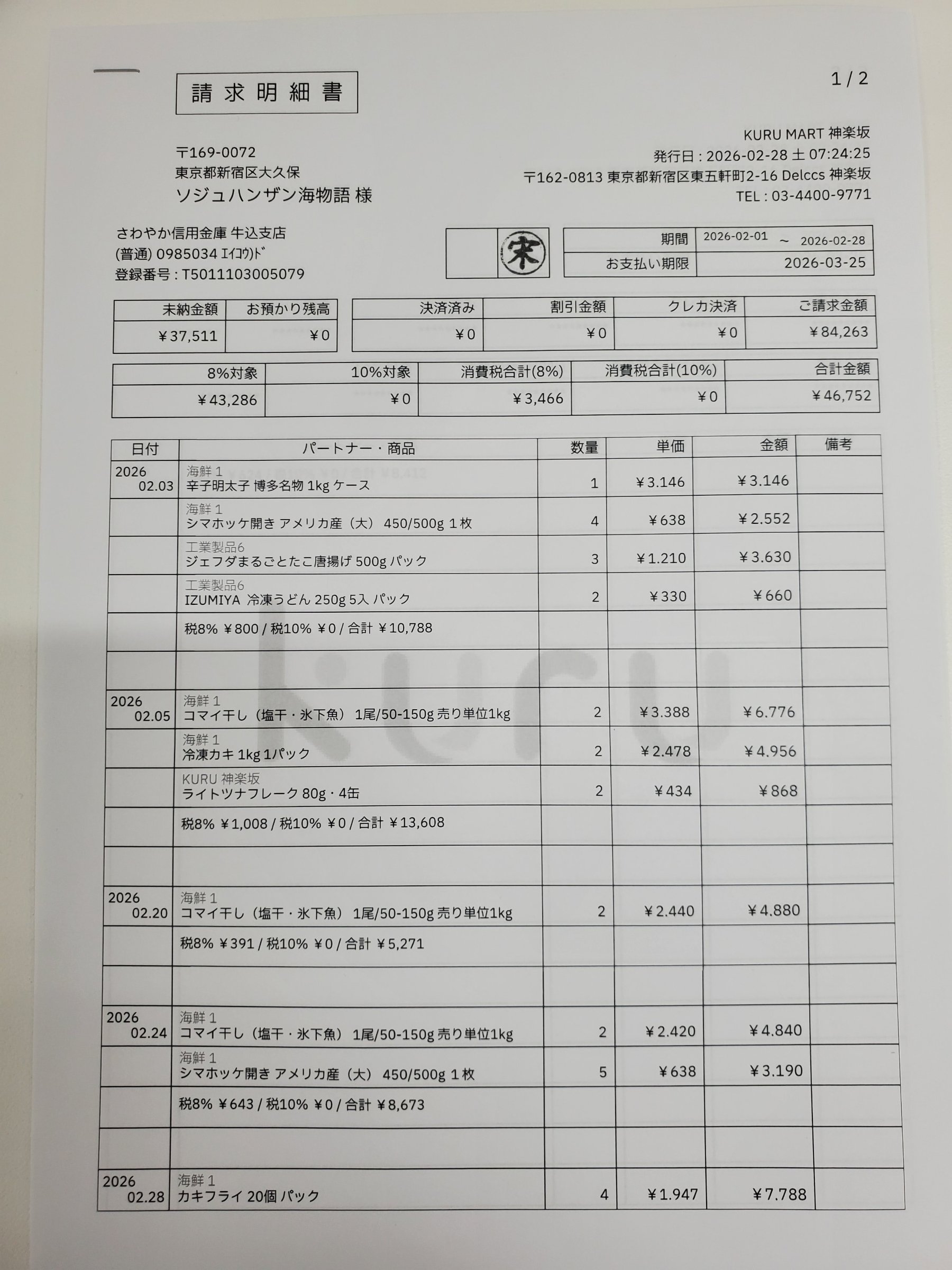
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
鉴权与基础 URL
公开 API 只有一个统一基础地址——https://api.space-ocr.com——没有 /v1 之类的路径版本号。每个请求都用 HTTP Bearer token 鉴权,密钥以 spocr_ 为前缀:
Authorization: Bearer spocr_xxxxxxxxxxxxxxxx
请求头缺失或格式错误会返回 401;密钥无法识别则返回 403。每个响应都带有一个 X-Request-Id 头(格式为 req_xxx),建议记录下来用于排查支持问题。完整规范以 OpenAPI 3.1 的形式发布在 GET /openapi.json,如果你想直接生成客户端代码可以用它。
最简单的调用:使用内置发票模板
最快的方式是 templateId: "invoice"——这是一个预定义结构,本身就知道发票长什么样,省得你自己描述字段。把图片以 URL 或纯 base64 的形式传入(imageType 会根据是否带 http(s):// 前缀自动判断),就能拿回强类型字段。
curl -X POST https://api.space-ocr.com/ocr/fields \
-H "Authorization: Bearer spocr_xxxxxxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"image": "https://example.com/invoices/inv-4471.jpg",
"imageType": "url",
"templateId": "invoice"
}'驼峰命名(camel-case)是规范写法。 参数为 imageType、templateId、autoFields。旧的下划线命名(snake_case)别名(image_type、template_id、auto_fields)仍可使用,但已弃用(deprecated)——新代码请优先使用驼峰命名。
响应结构
调用成功会返回 { status: "success", data: { ... } }。每个提取出的值都带有自己的溯源信息,而一个 field_bboxes 映射给出了每个字段的坐标:
bbox—— 一个轴对齐矩形{ xmin, ymin, xmax, ymax },基于 0–1000 normalized(归一化)网格(0,0 = 左上角,1000,1000 = 右下角),与图片的像素尺寸无关。换算成像素用pixel_x = bbox_x / 1000 × image_width。vertices—— 四个有序的点{x, y}(左上 → 右上 → 右下 → 左下),构成一个跟随文档倾斜的带方向的框,所以哪怕是歪着拍的手机照片,发票上的值也能被干净地框住。match_ratio—— 该值的字符中实际在页面上定位到的比例(0–1)。当达到 ≥ 0.85 时即视为高置信匹配;1.0表示每个字符都被找到了。bbox_source—— 坐标是如何得出的:vision_symbol_match(常规的字符匹配路径,携带其真实的match_ratio)、token_id/token_id_hybrid(用到了某个词元(word-token)提示)、low_confidence(弱匹配——值得复核),或shared_value(从合并单元格传播而来)。
{
"status": "success",
"data": {
"total": "2,045",
"field_bboxes": {
"total": {
"bbox": { "xmin": 595, "ymin": 974, "xmax": 781, "ymax": 1000 },
"vertices": [
{ "x": 594, "y": 975 }, { "x": 781, "y": 972 },
{ "x": 781, "y": 998 }, { "x": 595, "y": 1000 }
],
"match_ratio": 0.93,
"bbox_source": "vision_symbol_match"
}
}
}
}坐标并非照搬模型给出的文字。 语言模型会返回每个值的文本——以及它用到了哪些词元(word token)的提示——但从不返回框本身。引擎随后会把这段文本逐字符地与视觉 OCR 在页面上实际检测到的符号进行匹配;match_ratio 就是匹配上的比例,框则落在这些字符真正来源的像素上。模型的词元提示可能带噪声(它有时会在重复的行之间把它们搞混),所以系统用列一致性与行一致性检查来验证它们,而不是盲目采信。也就是说,一个值的坐标会被反过来对照发票核验,并附带一个表明匹配程度的分数。完整原理见为什么边界框让 OCR 可审计。
模板不够用时:自定义字段
真实发票上总有通用模板叫不出名字的字段——采购订单(PO)号、付款条款代码、项目标签等。这时你可以传入一个由 FieldSpec 对象组成的 fields 数组,替代模板(或与模板并用)。每个 FieldSpec 形如 { name, type, description?, children? }。如果你同时传了 fields 和 templateId,以 fields 为准。
description 是你引导模型的地方:用平实的自然语言说明要抓取什么、怎么抓。而 type: "array" 配上 children,正是抽取重复明细行(line items)的方式——一个子结构,对应多行。(我们在从发票中提取明细行一文中对此做了深入讲解。)
import requests, base64
with open("invoice.jpg", "rb") as f:
b64 = base64.b64encode(f.read()).decode()
resp = requests.post(
"https://api.space-ocr.com/ocr/fields",
headers={"Authorization": "Bearer spocr_xxxxxxxxxxxxxxxx"},
json={
"image": b64,
"imageType": "base64",
"fields": [
{"name": "vendor", "type": "string",
"description": "Supplier / billing company name"},
{"name": "invoice_no", "type": "string",
"description": "Invoice number, verbatim"},
{"name": "invoice_date", "type": "string"},
{"name": "total", "type": "string",
"description": "Grand total, keep comma separators"},
{"name": "line_items", "type": "array",
"description": "One row per line on the invoice",
"children": [
{"name": "description", "type": "string"},
{"name": "qty", "type": "number"},
{"name": "unit_price", "type": "number"},
]},
],
},
timeout=60,
)
data = resp.json()["data"]
print(data["total"], data["field_bboxes"]["total"]["match_ratio"])值会被原样保留。 合计 7,855 会原封不动地以字符串 "7,855" 返回——逗号分隔符、小数点和全角字符都保持不变。只有当某个字段的 description 明确要求时,引擎才会做归一化处理。你在网页界面里看到的 ¥ 只是装饰,不属于值本身。引擎只接受栅格图像——JPEG、PNG、GIF、BMP、TIFF、WebP——并会自动转换为 RGB。
走异步:批量上传、任务与 Webhook
POST /ocr/fields 是同步的,非常适合在一次请求/响应循环里处理单张发票。如果是一整个文件夹的发票,可以用 POST /upload 把它们提交到一个表格(sheet)里(multipart 形式、可重复的 files)。默认情况下它会立即返回一个 jobs 数组:
{ "path": "...", "jobs": [ { "uniqueKey": "...", "jobId": "...", "status": "pending" } ] }
之后你有两种方式得知结果:轮询 GET /jobs/{jobId},或者注册一个 webhook。Webhook 是每个空间一个 URL,通过 X-Spaceocr-Signature 头做 HMAC-SHA256 签名。你会关心的事件有 upload.received、item.created、ocr.completed(其 data.result 携带提取结果)以及 ocr.failed。在信任任何 payload 之前,请务必先验证签名。
幂等性、请求追踪与限流
有几个请求头能让生产流程安全地重试:
| Header | 用途 |
|---|---|
Idempotency-Key | 在 /upload 和 /create 上,用相同的 key 重发会在 24 小时内重放缓存的响应(X-Idempotent-Replay: true)——重试安全、不会重复扣费。 |
X-Request-Id | 每个响应都会返回(req_xxx);记录下来以便排查问题。 |
限流为 每个密钥 60 次/分钟、每个 uid 600 次/分钟,采用固定的 60 秒窗口。超出后会返回 429,带 error.code: "rate_limited"。等待时间在 JSON body 里以 details.retryAfterSec 给出——没有 Retry-After HTTP 头,所以请根据 body 里的值来退避(back off)。
{
"error": {
"code": "rate_limited",
"message": "Rate limit exceeded",
"requestId": "req_8fa2c1"
},
"details": { "retryAfterSec": 12 }
}从提取到可查询的表格
一旦发票被提取进表格,你就不必为了再读取它们而重跑 OCR。GET /view 会对已存储的行做服务端查询——where、sort、select、limit、offset——不收费、也不会重新提取。边界框默认会随结果一并返回;想要更精简的 payload 可以加上 boxes=0。从那里你还能导出为 CSV(UTF-8 BOM,所以 Excel 和中日韩文本都能正常打开)——参见把扫描文档转成 CSV。
定价
POST /ocr/fields 每次调用收费 ¥10,POST /upload 为 ¥10 × N 张图片。失败不收费——如果 OCR 没有返回结果,会予以退款;502 引擎错误或 ocr.failed 事件也会自动退款。只读接口(GET /space、/view、/amount、/health)免费。免费档为每月 100 次扫描、无需信用卡;Pro 档为 ¥7,980/月;Business 档为联系销售。
如何用 API 从发票中提取数据
- 获取 API 密钥登录后生成一个以 spocr_ 为前缀的密钥。每个请求都通过 HTTP Bearer token 鉴权:Authorization: Bearer spocr_xxxxxxxxxxxxxxxx。
- 准备发票图片提供一个公开可访问的 URL,或把图片编码为纯 base64。引擎接受栅格图像——JPEG、PNG、GIF、BMP、TIFF、WebP——imageType 会根据是否带 http(s):// 前缀自动判断。
- 调用 POST /ocr/fields向 https://api.space-ocr.com/ocr/fields 发送 POST 请求,传入 templateId 'invoice' 套用内置发票模板,或传入一个自定义的 fields[] 结构。这是一次同步调用,会直接返回结果。
- 读取字段及其边界框从响应的 data 中读取每个值,并从 field_bboxes 中读取对应坐标。每个字段都带有一个 bbox、带方向的 vertices,以及一个 match_ratio,用于将该值对照页面核验。
- 扩展到批量与查询如需处理多张发票,用 POST /upload 把它们提交到一个表格,再通过轮询 GET /jobs/{jobId} 或注册 webhook 获取结果。之后用 GET /view 查询已存储的行,或导出为 CSV。