검증할 수 있는 데이터를 돌려주는 OCR API
REST 호출 한 번으로, 각 필드에 바운딩 박스·4꼭짓점·일치 점수가 붙은 구조화 JSON이 돌아옵니다. Bearer 인증, 내장 템플릿, 비동기 작업, 서명 웹훅.
대부분의 OCR API는 페이지 전체 텍스트 덩어리와 신뢰도 점수 하나를 돌려줄 뿐입니다. 세금계산서 합계를 찾고, 파싱하고, 제자리에 들어갔기를 바라는 일은 결국 여러분 몫으로 남습니다. space-ocr의 OCR API는 그 구조화까지 해줍니다. 이미지와 템플릿을 한 번 POST하면 타입이 있는 필드가 JSON으로 돌아옵니다.
프로덕션에서 진짜 중요한 건 각 값에 무엇이 따라오느냐입니다. 모든 필드가 페이지에서 읽어낸 정확한 박스, 그 박스의 네 모서리, 그리고 일치 점수와 함께 돌아옵니다. 그래서 파이프라인은 모델의 말을 믿을 필요 없이, 각 값을 문서 위 실제 위치와 대조해 확인할 수 있습니다.
직접 살펴볼 수 있는 실제 응답
아래 어느 필드든 마우스를 올려 보세요 — 세금계산서 위의 박스가 그 값을 읽어낸 지점입니다. 이것은 실제 파싱 결과입니다. 청구처명 ソジュハンザン海物語様, 청구 금액 ¥84,263, 합계 ¥46,752, 각 품목 — 모두 자기 박스와 일치 점수와 함께 돌아옵니다. 목업이 아닙니다.
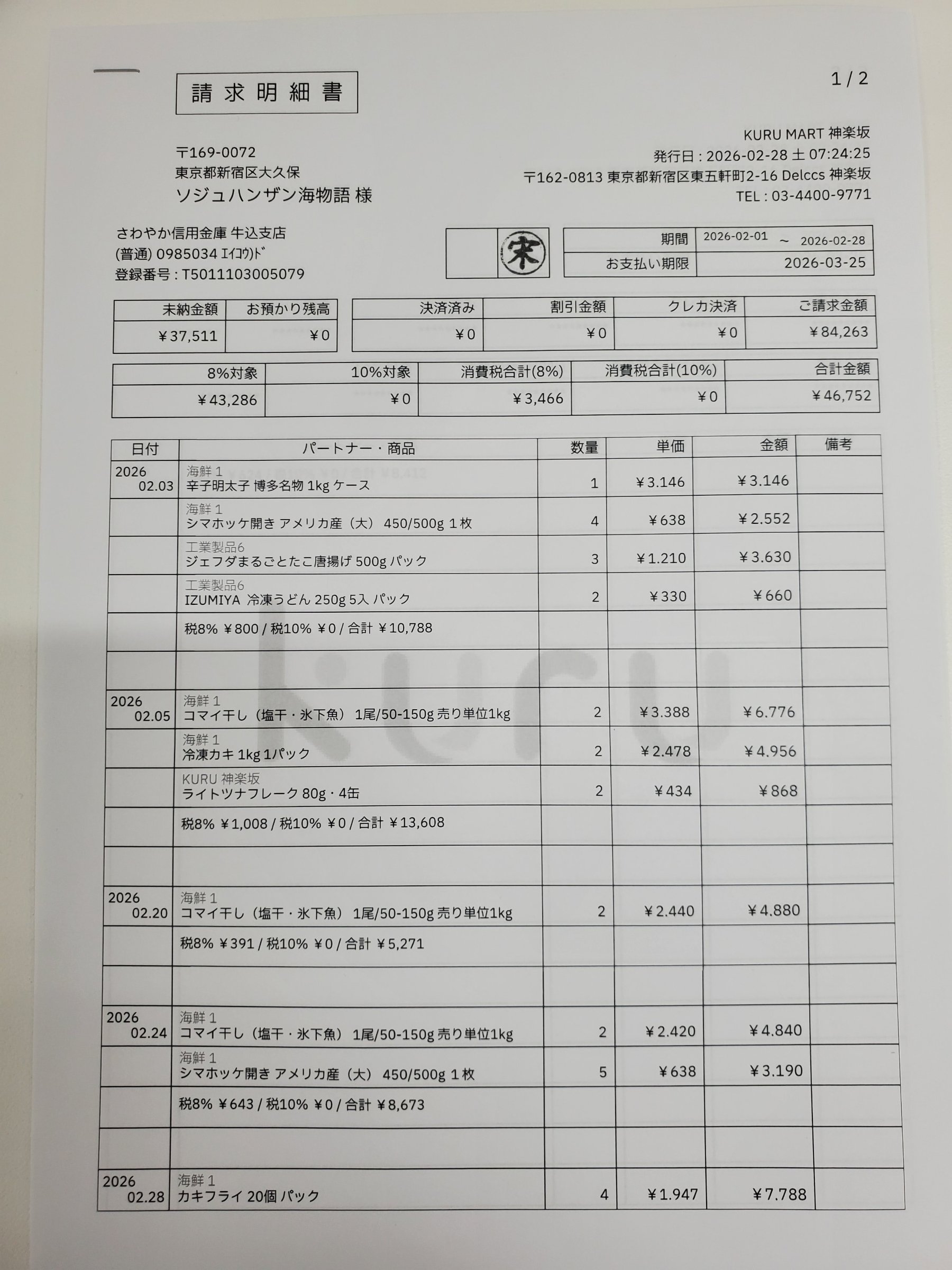
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
space-ocr의 OCR API 작동 방식
Bearer 토큰으로 인증합니다 — 키는 spocr_로 시작하고, 베이스 URL은 https://api.space-ocr.com입니다. 래스터 이미지 한 장을 URL이나 base64로 POST /ocr/fields에 보냅니다(공개 API는 이미지 — JPEG·PNG·GIF·BMP·TIFF·WebP — 를 받으므로 PDF라면 페이지 이미지를 보냅니다). 내장 templateId나 직접 만든 fields를 넘기면, 필드마다 값·bbox·vertices·match_ratio가 담긴 { status: 'success', data: {...} }가 돌아옵니다.
좌표는 모델이 지어낸 것이 아닙니다. LLM은 각 값과 사용한 word-token id만 반환합니다. 그다음 문자 매처가 그 값을 Google Vision이 실제로 페이지에서 검출한 심볼과 대조하고, 커버리지를 match_ratio로 매깁니다. 0.85 이상이면 확실한 매칭이고, 1.0은 모든 글자를 페이지에서 찾았다는 뜻입니다. 모든 응답에 X-Request-Id 헤더가 붙고, 오류는 { error: { code, message, requestId } }로 돌아옵니다.
curl -s https://api.space-ocr.com/ocr/fields \
-H "Authorization: Bearer $SPACE_OCR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice"
}'import os, requests
resp = requests.post(
"https://api.space-ocr.com/ocr/fields",
headers={"Authorization": f"Bearer {os.environ['SPACE_OCR_API_KEY']}"},
json={
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice",
},
timeout=60,
)
resp.raise_for_status()
for name, field in resp.json()["data"].items():
print(name, field["value"], field["bbox"], field["match_ratio"])OCR API를 호출하는 방법
- API 키 받기로그인해 키를 만듭니다 — spocr_로 시작합니다. https://api.space-ocr.com 으로의 모든 요청에 Authorization: Bearer <key>로 보냅니다.
- 이미지 보내기POST /ocr/fields에 image(URL 또는 순수 base64)와 imageType을 보냅니다. PDF는 페이지 이미지를 보내세요 — API는 래스터 형식(JPEG·PNG·GIF·BMP·TIFF·WebP)을 받습니다.
- 템플릿 또는 필드 선택'invoice'나 'receipt' 같은 내장 templateId를 넘기거나, 직접 fields를 지정합니다 — 품목 표에는 children이 있는 array 필드를 포함합니다.
- 구조화 결과 읽기각 값에 bbox·vertices·match_ratio·bbox_source가 붙은 { status: 'success', data: {...} }가 반환됩니다. match_ratio에 임계값을 걸어 0.85 미만을 가려낼 수 있습니다.
- 확장과 조회POST /upload로 많은 이미지를 큐에 넣고(파일마다 작업, 서명 웹훅 또는 GET /jobs/{jobId}), 저장된 시트를 GET /view로 where·sort·select를 써서 읽습니다 — OCR 재실행도 추가 비용도 없습니다.
단순하고 예측 가능한 가격
이미지당 ₩100(¥10 / $0.05), 신용카드 없이 월 100회 스캔 무료 플랜 포함. 저장된 시트를 GET /view로 다시 읽는 것은 OCR 재실행이 아니라 무과금입니다. 정액 플랜은 월 스캔 수·시트·저장공간을 추가합니다.