스캔 문서를 CSV로 변환하는 방법
스캔 문서를 CSV로 변환하는 방법을 알아보세요. 열(컬럼)을 한 번만 정의하고 사진이나 스캔본을 올리면 문서마다 한 행이 채워집니다. Excel과 한중일(CJK) 텍스트가 깨지지 않는 UTF-8 CSV로 내보내세요.
종이 더미가 쌓여 있습니다 — 청구서, 영수증, 납품서. 이걸 스프레드시트의 행으로 만들어야 하죠. 일일이 다시 타이핑하는 건 느리고 실수가 잦고, 일반적인 OCR 도구는 원시 텍스트 덩어리만 쏟아낼 뿐이라 결국 직접 열로 정리해야 합니다. 정작 필요한 작업은 더 좁고 더 쓸모 있습니다: 문서 사진이나 스캔본을, 매번 올바른 값이 올바른 열에 들어간 깔끔한 CSV 행으로 바꾸는 것.
이 가이드가 바로 그걸 다룹니다. 열을 한 번만 정의하고, space-ocr에 이미지를 건네면, 문서마다 한 행이 자동으로 채워집니다. 작업이 끝나면 시트 전체를 CSV로 내보냅니다 — 바이트 순서 표시(BOM)가 붙은 UTF-8이라 Excel과 한중일(CJK) 텍스트가 깔끔하게 열립니다. 다시 타이핑할 일도 없고, 모든 값은 페이지에서 어디에 있었는지까지 거슬러 추적할 수 있습니다.
작업 흐름의 큰 그림
스캔 문서를 CSV로 변환하는 일은 네 단계로 나뉩니다.
- 사진 촬영 또는 스캔 — 래스터 이미지(JPEG, PNG, TIFF 등). 휴대폰 사진이면 충분하고, 자동 회전이 옆으로 누운 사진까지 처리합니다.
- 열을 한 번만 정의 — 필요한 필드에 이름을 붙입니다(
vendor,date,total, 라인 아이템…). 이것이 모든 문서를 읽어 들이는 기준 스키마가 됩니다. - 업로드 — 각 이미지가 읽히고, 그 값들이 정의한 열 아래 새 행으로 들어갑니다. 문서마다 따로 설정할 필요가 없습니다.
- CSV 내보내기 — 시트 전체를
<sheetName>.csv로 내려받아 어디서든 엽니다.
핵심은 일관성입니다. 열을 미리 고정해 두기 때문에, 열 번째 영수증도 첫 번째와 똑같은 모양으로 들어갑니다.
먼저 증거부터: 모든 값은 출처를 안다
단계로 들어가기 전에, 왜 이 결과를 믿어도 되는지부터 보여 드립니다. 아래 아무 필드에나 마우스를 올려 보세요 — 영수증 위의 박스가 그 값이 읽힌 정확한 위치를 가리키고, 각 필드에는 매치 비율(match ratio) 이 함께 붙어 있습니다. CSV는 그 안의 숫자를 근거로 설명할 수 있어야 비로소 쓸모가 있는데, 여기서는 모든 셀이 원본 픽셀까지 거슬러 추적됩니다.
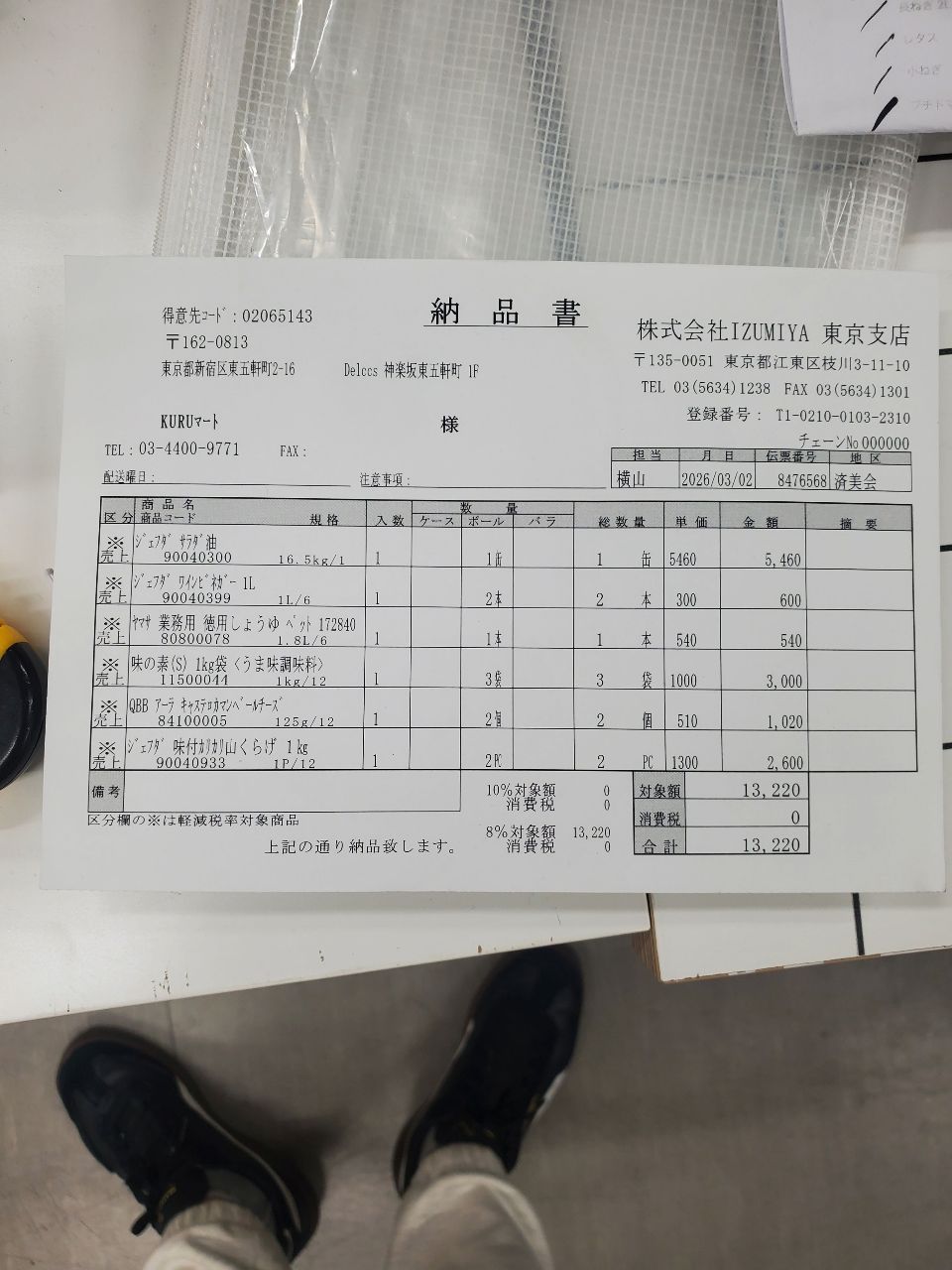
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
스캔 문서를 CSV로 변환하는 단계별 방법
1. 문서를 이미지로 캡처한다
space-ocr는 래스터 이미지 를 읽습니다 — JPEG, PNG, GIF, BMP, TIFF, WebP. 책상 위에서 영수증을 찍든, 청구서를 PNG로 스캔하든, 스캐너 앱에서 페이지를 내보내든 됩니다. 스캔 PDF도 앱에 그대로 드롭하면 각 페이지가 자동으로 이미지화됩니다. 비스듬히 찍은 휴대폰 사진도 괜찮습니다: 엔진이 EXIF 방향 정보를 읽어 회전을 보정하므로, 옆으로 누운 사진도 똑바로 읽히고 값도 제자리에 맞춰 고정됩니다.
2. 열을 한 번만 정의한다
바로 이 단계가 OCR을 깔끔한 표로 바꿔 줍니다. 열 스키마가 있는 시트를 만드세요 — CSV 헤더가 될 필드들입니다. 스칼라 열은 단일 값(vendor, invoice_date, total)이고, 배열 열은 반복되는 라인 아이템 을 담습니다. 한 번만 정의하면, 이후 업로드하는 모든 문서가 동일한 열을 기준으로 읽힙니다.
vendor (string)
invoice_date (string)
total (string)
items (array) → name, unit_price, qty
스키마를 직접 짜기 번거롭다면, 내장 템플릿(invoice, receipt, business_card 등)이 흔한 문서 유형에 맞는 필드와 프롬프트를 제공합니다. 특히 청구서라면 청구서에서 라인 아이템 추출하기를 참고하세요.
3. 업로드 — 행이 스스로 채워진다
열이 준비됐으면, 시트에 이미지를 업로드합니다. 각 문서가 한 행이 됩니다: 엔진이 페이지를 읽어 각 값을 맞는 열 아래에 끼워 넣습니다. 영수증 스무 장을 넣으면 같은 모양의 행 스무 개가 나옵니다. 라인 아이템 배열은 행의 구조화된 하위 항목으로 보관되어, 내보낼 때 펼쳐질 준비가 되어 있습니다.
값은 있는 그대로 돌아옵니다 — 7,855는 쉼표를 그대로 유지하고, 전각 문자와 경칭도 보존됩니다 — 그래서 CSV는 다시 포맷한 추정값이 아니라 인쇄된 내용을 그대로 비춥니다.
4. CSV로 내보내기
내보내기를 클릭하면 시트가 <sheetName>.csv로 내려받아집니다. 헤더 행은 스키마에서 곧바로 만들어집니다.
- 맨 앞의
#열(행 인덱스). - 각 스칼라 열 이름 을 적은 그대로.
- 각 배열 하위 항목 은
colName.childName으로 평탄화 — 즉name과unit_price를 가진items배열은items.name,items.unit_price열이 됩니다.
라인 아이템 배열을 포함한 행은 하위 행으로 펼쳐집니다 — 부모의 스칼라 값은 한 번만 나타나고 각 라인 아이템이 그 아래 자기 행을 갖습니다. 그래서 라인이 여덟 개인 청구서는 하나의 vendor와 date 아래 여덟 개의 CSV 행이 됩니다. 파일은 바이트 순서 표시(BOM)가 붙은 UTF-8 로 작성되며, 바로 이 점 덕분에 Excel과 일본어·한국어·중국어 텍스트가 글자 깨짐 없이 열립니다.
셀을 직접 수정했다면, 내보내기에서 수동으로 입력한 값이 원래 OCR 값을 덮어쓰므로, 수정 사항이 그대로 CSV에 반영됩니다.
CSV는 추정이 아니라 직접 정의한 열에서 만들어집니다. 헤더는 스키마에서 나오고(# + 스칼라 이름 + 라인 아이템의 array.child), 배열 행은 하위 행으로 펼쳐지며, 파일은 BOM이 붙은 UTF-8로 출력되어 Excel과 한중일(CJK) 텍스트가 깔끔하게 열립니다. 수동 편집은 내보내기에서 OCR 값을 덮어씁니다 — 열 모양은 정의하는 순간 고정되고, 그래서 모든 다운로드가 예측 가능합니다.
API로 처리하기
같은 흐름을 화면 없이도 그대로 쓸 수 있습니다. 열이 있는 시트를 만들고, 이미지를 업로드한 뒤, GET /view로 구조화된 행을 가져옵니다 — 서버 측에서, OCR을 다시 돌리지 않고, 추가 과금 없이. 거기서 CSV를 직접 작성하거나, 시트의 CSV 내보내기를 받으면 됩니다. GET /view는 내보내기 전에 필터(where), 정렬, 열 선택도 지원하므로, 필요한 행만 골라서 내보낼 수 있습니다.
# 1. Create a sheet with the columns you want as CSV headers
curl -X POST https://api.space-ocr.com/create \
-H "Authorization: Bearer $SPACE_OCR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"path": "/invoices",
"type": "sheet",
"name": "june-invoices",
"columns": [
{ "name": "vendor", "type": "string" },
{ "name": "invoice_date", "type": "string" },
{ "name": "total", "type": "string" },
{ "name": "items", "type": "array",
"children": [
{ "name": "name", "type": "string" },
{ "name": "unit_price", "type": "string" }
] }
]
}'
# 2. Upload document images — each one fills a row
curl -X POST https://api.space-ocr.com/upload \
-H "Authorization: Bearer $SPACE_OCR_API_KEY" \
-F "path=/invoices/june-invoices" \
-F "files=@invoice-01.png" \
-F "files=@invoice-02.jpg"행이 들어가면 GET /view가 그 행들을 구조화된 JSON으로 돌려주는데, 이를 바로 CSV로 작성하거나 회계 시스템에 넘길 수 있습니다. 추출 엔드포인트와 필드 명세에 대한 전체 안내는 청구서 데이터 추출 API 가이드와 API 문서를 참고하세요.
스캔 PDF, 그리고 입력에 관한 참고
space-ocr 엔진은 PDF 바이트가 아니라 래스터 이미지 를 처리합니다 — 다만 앱에서는 그걸 신경 쓸 필요가 없습니다. 스캔된 PDF를 끌어다 놓으면 각 페이지가 OCR 전에 자동으로 이미지로 래스터화됩니다. 공개 API를 직접 호출할 때만 각 페이지를 먼저 이미지(PNG 또는 JPEG)로 렌더링해 업로드하면 됩니다. 목표가 CSV가 아니라 특히 Excel이라면, 같은 흐름이 그대로 적용됩니다 — 스캔 PDF를 Excel로 변환하기에서 단계별로 살펴보세요. CSV는 가장 마찰이 적은 목적지입니다: 어디서든 열리고, BOM이 붙은 UTF-8 내보내기 덕분에 인코딩 문제로 놀랄 일이 없습니다.
- 문서를 이미지로 캡처한다각 문서를 래스터 이미지(JPEG, PNG, TIFF 등)로 촬영하거나 스캔합니다. 휴대폰 사진이면 충분합니다 — EXIF 자동 회전이 옆으로 누운 사진을 보정합니다. 스캔된 PDF도 됩니다. PDF를 space-ocr 앱에 끌어다 놓으면 각 페이지가 자동으로 래스터화됩니다(API를 직접 호출할 때만 각 페이지를 먼저 이미지로 렌더링하면 됩니다).
- 열을 한 번만 정의한다열 스키마가 있는 시트를 만듭니다: vendor, date, total 같은 스칼라 열에, 반복되는 라인 아이템을 위한 배열 열을 더합니다. 이것이 CSV 헤더가 되고 모든 문서에 재사용됩니다.
- 이미지를 업로드한다문서 이미지를 시트에 업로드합니다. 각 이미지가 읽히고 그 값들이 정의한 열 아래 새 행을 자동으로 채웁니다 — 문서마다 설정할 필요가 없고, 값은 있는 그대로 보존됩니다.
- CSV로 내보낸다시트를 내보냅니다. # 에 스칼라 열 이름, 그리고 배열 하위 항목을 colName.childName으로 더한 헤더와 함께 <sheetName>.csv로 내려받아집니다. 라인 아이템 행은 하위 행으로 펼쳐지고, 파일은 BOM이 붙은 UTF-8이라 Excel과 한중일(CJK) 텍스트가 깔끔하게 열립니다.
스캔 문서를 CSV로 어떻게 변환하나요?
CSV가 Excel에서 일본어나 중국어 텍스트까지 제대로 열리나요?
라인 아이템은 CSV에서 어떻게 처리되나요?
스캔된 PDF를 CSV로 변환할 수 있나요?
문서마다 열을 정의해야 하나요?
스캔 문서를 CSV로 바꿔 보세요
열을 한 번 정의하고, 업로드하고, 내보내세요. 무료 플랜 — 매달 100 스캔, 신용카드 불필요. 모든 값이 페이지 내 위치와 함께 돌아옵니다.