Python으로 송장 분석: REST API 활용 가이드
Python을 사용하여 송장에서 구조화된 데이터를 추출하는 방법을 알아보세요. 간단한 REST API를 호출하여 송장 이미지로부터 JSON 필드, 품목 리스트, 그리고 검증 가능한 위치 좌표까지 얻는 전체 과정을 안내합니다.
송장에서 정형 데이터를 추출하는 작업은 흔하지만 매우 번거로운 일입니다. 스캔한 영수증이나 거래처 청구서가 담긴 폴더를 열어보면 JPEG나 PNG 파일이 가득하죠. 회계 처리나 데이터 분석을 위해 송장 번호, 총액, 각 라인 아이템을 뽑아내야 합니다. 대부분의 OCR 툴은 텍스트 덩어리만 쏟아낼 뿐, 깨지기 쉬운 정규 표현식으로 일일이 구조를 재조립해야 하는 수고로움이 따릅니다.
더 직접적인 방법이 있습니다. 필요한 구조화된 JSON을 반환하는 REST API를 호출하는 것입니다. 모든 값은 페이지상의 정확한 위치 정보와 함께 제공됩니다. 아래의 인터랙티브 데모에서 최종 결과를 확인해 보세요. 왼쪽 필드를 클릭하면 송장에서 해당 위치가 강조 표시됩니다.
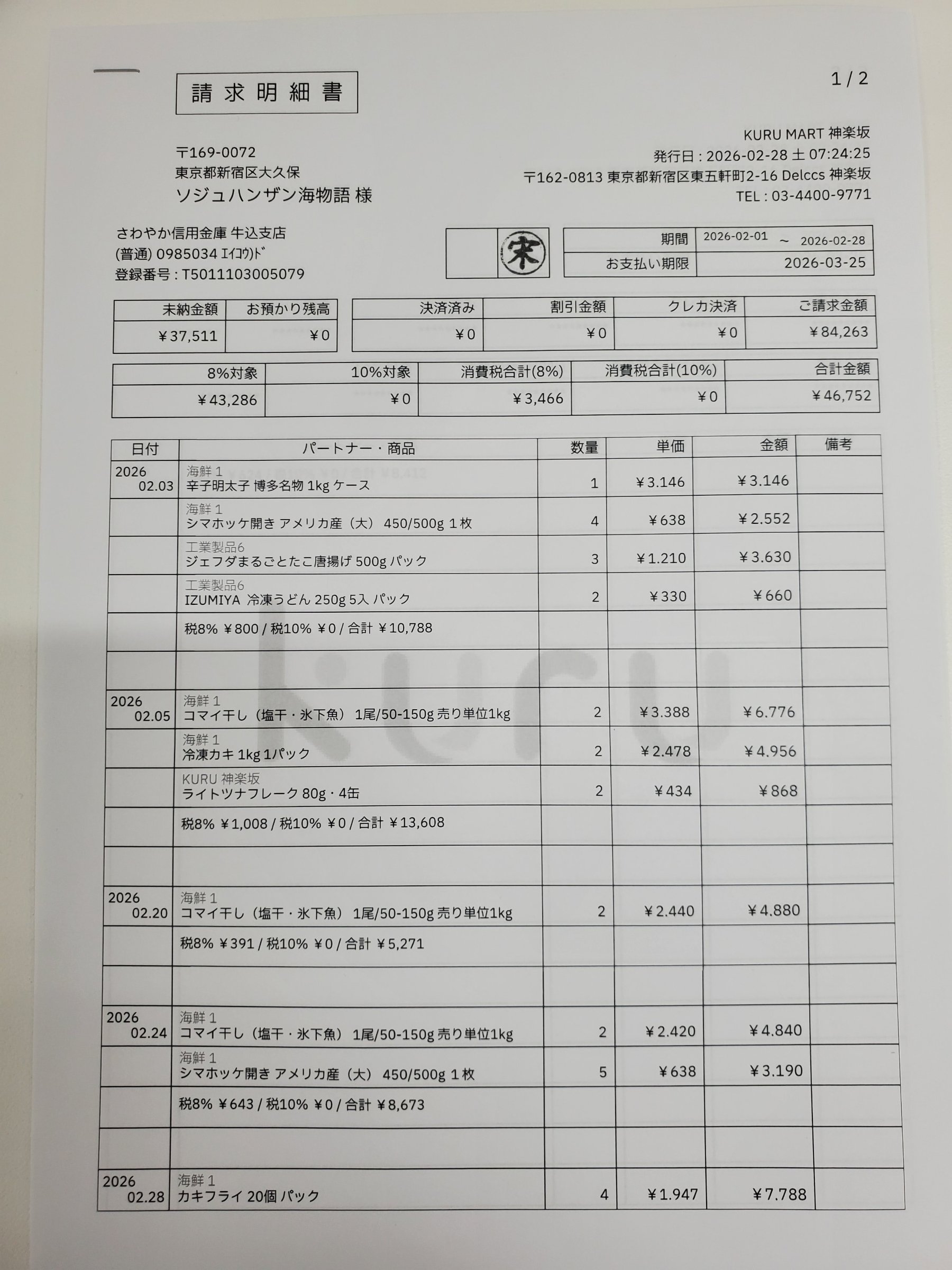
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
space-ocr는 설치형 라이브러리가 아닌, 일반적인 HTTP 서비스입니다. 과정은 간단합니다. 송장 이미지를 POST /ocr/fields 엔드포인트로 보내고, 받고자 하는 데이터의 스키마를 정의하기만 하면 됩니다. invoice_number, total_due 같은 필드와 설명, 가격 등의 열을 가진 line_items 테이블을 지정할 수 있습니다. API는 이 스키마에 맞춰 깔끔한 JSON 객체를 반환합니다.
각 필드에 대한 응답에는 "20250430-001"과 같은 invoice_number 텍스트 값뿐만 아니라, 해당 값의 좌표와 신뢰도 점수도 포함됩니다. 이 match_ratio는 추출된 텍스트가 페이지에서 발견된 문자와 얼마나 잘 일치하는지를 알려주어, 데이터 품질에 대한 신뢰할 수 있는 지표가 됩니다. 아래 Python 스크립트는 이 모든 과정을 처음부터 구현하는 방법을 보여줍니다.
import os
import base64
import requests
import json
# Get your API key from an environment variable
API_KEY = os.environ.get("SPACE_OCR_API_KEY")
IMAGE_PATH = "./path/to/your/invoice.jpg" # Path to your invoice image
API_URL = "https://api.space-ocr.com/ocr/fields"
if not API_KEY:
raise ValueError("API key not found. Set the SPACE_OCR_API_KEY environment variable.")
# Define the schema for the data you want to extract
# For line items, use type 'array' and define columns in 'children'
fields_schema = [
{"name": "supplier", "type": "string", "description": "The name of the company that issued the invoice."},
{"name": "invoice_number", "type": "string"},
{"name": "issue_date", "type": "date"},
{"name": "total_due", "type": "number"},
{
"name": "line_items",
"type": "array",
"description": "All items listed in the invoice table.",
"children": [
{"name": "item_description", "type": "string"},
{"name": "unit_price", "type": "number"},
{"name": "quantity", "type": "number"},
{"name": "line_total", "type": "number"}
]
}
]
# Read the image file and encode it in base64
with open(IMAGE_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"image": base64_image,
"imageType": "base64",
"fields": fields_schema
}
print(f"Sending request for {IMAGE_PATH}...")
response = requests.post(API_URL, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()['data']
print("\n--- Extracted Invoice Data ---")
for field_name, field_data in result.items():
if isinstance(field_data, list):
print(f"\n{field_name}:")
for i, row in enumerate(field_data):
print(f" - Item {i+1}:")
for col_name, col_data in row.items():
print(f" {col_name}: {col_data['value']} (Confidence: {col_data['match_ratio']:.2f})")
else:
print(f"{field_name}: {field_data['value']} (Confidence: {field_data['match_ratio']:.2f})")
# Bounding box is available at field_data['bbox']
# e.g., print(f" bbox: {field_data['bbox']}")
else:
print(f"Error: {response.status_code}")
print(response.text)정확도를 보장하기 위해 space-ocr는 언어 모델의 출력을 그대로 신뢰하지 않습니다. 모델은 텍스트 값과 함께 페이지에서 어떤 단어를 사용했는지에 대한 힌트를 반환합니다. 그러면 엔진은 추출된 값을 페이지의 실제 OCR 기호와 문자 단위로 대조합니다. 이 과정을 통해 match_ratio 신뢰도 점수(0.85 이상은 높은 신뢰도의 일치로 간주)와 최종 바운딩 박스가 생성됩니다. 모든 좌표(xmin, ymin, xmax, ymax)는 0-1000 스케일로 정규화되어 원본 이미지 해상도와 무관하게 사용할 수 있습니다.
API 가격은 필드 수나 페이지 복잡도가 아닌 호출 건당으로 책정됩니다. 이미지당 100원이며, 결과 추출에 실패한 요청은 과금되지 않습니다. 신규 계정에는 매월 100건의 무료 스캔이 제공됩니다.
- API 키 발급받기space-ocr에 무료로 가입하고 대시보드 설정에서 API 키를 확인하세요. 키는 'spocr_'로 시작합니다.
- 송장 이미지 준비하기송장을 JPEG나 PNG와 같은 일반적인 이미지 파일로 저장하세요. 스크립트에서 사용할 파일 경로를 기록해 둡니다.
- 데이터 스키마 정의하기Python 스크립트에서 추출하려는 필드의 이름과 타입을 정의하는 JSON 배열을 만드세요. 라인 아이템 테이블도 여기에 포함됩니다.
- Python 스크립트 작성하기requests 라이브러리를 사용하여 이미지를 읽고 base64로 변환한 후, Authorization 헤더에 API 키를 담아 https://api.space-ocr.com/ocr/fields로 POST 요청을 보내는 스크립트를 작성하세요.
- 실행 및 JSON 처리하기스크립트를 실행하세요. 구조화된 JSON 응답이 출력되며, 이 데이터를 데이터베이스, 회계 소프트웨어 또는 분석 도구에 로드할 수 있습니다.