検証できるデータを返すOCR API
1回のRESTコールで、各フィールドにバウンディングボックス・4頂点・マッチ率が付いた構造化JSONが返ります。Bearer認証、組み込みテンプレート、非同期ジョブ、署名付きWebhook。
ほとんどのOCR APIは、ページ全体のテキストの塊と1つの信頼度スコアを返すだけです。請求書の合計を探し、パースし、正しい場所に入ったことを祈る——その作業は結局あなたの側に残ります。space-ocrのOCR APIは、その構造化までやります。画像とテンプレートを1回POSTすれば、型付きフィールドがJSONで返ります。
本番で効いてくるのは、各値に何が付いてくるかです。すべてのフィールドが、ページ上のどこから読み取ったかという正確なボックス、その4つの角、そしてマッチ率とともに返ります。だからパイプラインはモデルの言い分を信じる必要がなく、各値を書類上の実際の位置と照らして確認できます。
その場で確認できる、実際のレスポンス
下のフィールドにマウスを合わせてみてください——請求書上のボックスが、その値を読み取った場所です。これは実際の解析結果です。請求先名 ソジュハンザン海物語様、ご請求金額 ¥84,263、合計金額 ¥46,752、各明細行——すべてが自分のボックスとマッチ率とともに返っています。モックアップではありません。
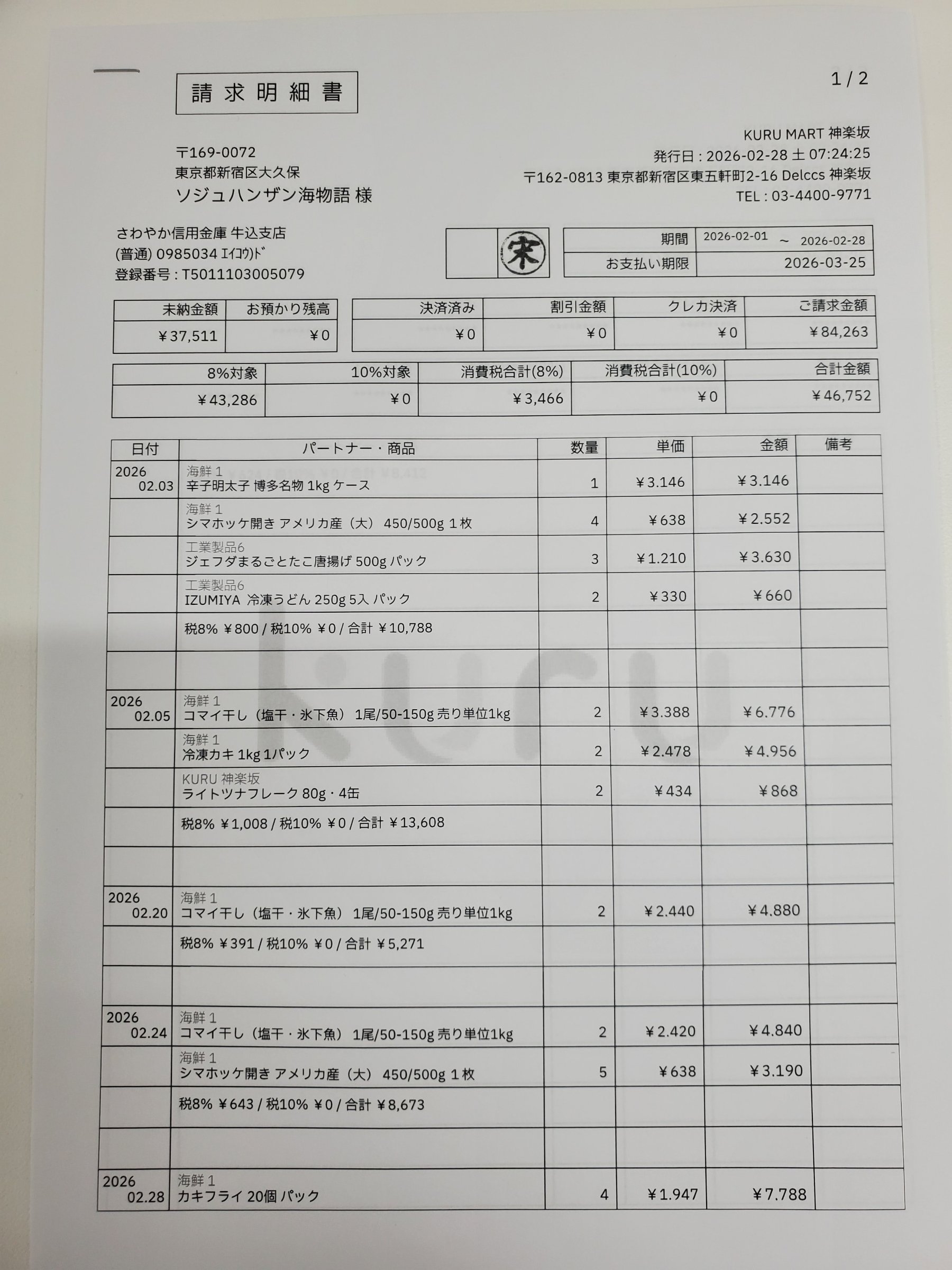
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
space-ocrでのOCR APIの仕組み
Bearerトークンで認証します——キーは spocr_ で始まり、ベースURLは https://api.space-ocr.com です。ラスター画像を1枚、URLまたはbase64で POST /ocr/fields に送ります(公開APIは画像——JPEG・PNG・GIF・BMP・TIFF・WebP——を受け付けるので、PDFならページ画像を送ります)。組み込みの templateId か独自の fields を渡せば、フィールドごとに値・bbox・vertices・match_ratio が入った { status: 'success', data: {...} } が返ります。
座標はモデルが作ったものではありません。LLMは各値と、使ったword-token IDを返すだけ。そのうえで文字マッチャーが、その値をGoogle Visionが実際にページで検出したシンボルと突き合わせ、カバレッジを match_ratio として採点します。0.85以上で確実なマッチ、1.0はすべての文字がページ上で見つかったことを意味します。すべてのレスポンスに X-Request-Id ヘッダが付き、エラーは { error: { code, message, requestId } } で返ります。
curl -s https://api.space-ocr.com/ocr/fields \
-H "Authorization: Bearer $SPACE_OCR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice"
}'import os, requests
resp = requests.post(
"https://api.space-ocr.com/ocr/fields",
headers={"Authorization": f"Bearer {os.environ['SPACE_OCR_API_KEY']}"},
json={
"image": "https://example.com/invoice.png",
"imageType": "url",
"templateId": "invoice",
},
timeout=60,
)
resp.raise_for_status()
for name, field in resp.json()["data"].items():
print(name, field["value"], field["bbox"], field["match_ratio"])OCR APIを呼び出す手順
- APIキーを取得サインインしてキーを作成します——spocr_ で始まります。https://api.space-ocr.com への毎リクエストに Authorization: Bearer <key> として送ります。
- 画像を送るPOST /ocr/fields に image(URLまたは純粋なbase64)と imageType を送ります。PDFはページ画像を送ってください——APIはラスター形式(JPEG・PNG・GIF・BMP・TIFF・WebP)を受け付けます。
- テンプレートまたはフィールドを選ぶ'invoice' や 'receipt' といった組み込み templateId を渡すか、独自の fields を指定します——明細行テーブルには children を持つ array フィールドを含めます。
- 構造化された結果を読む各値に bbox・vertices・match_ratio・bbox_source が付いた { status: 'success', data: {...} } が返ります。match_ratio にしきい値をかけ、0.85未満を要確認として洗い出せます。
- スケールとクエリPOST /upload で多数の画像をキューに入れ(ファイルごとにジョブ、署名付きWebhookまたは GET /jobs/{jobId})、保存済みシートを GET /view で where・sort・select を使って読みます——OCR再実行も追加料金もありません。
シンプルで予測できる料金
1枚あたり¥10($0.05 / ₩100)、クレジットカード不要・月100スキャンの無料枠付き。保存済みシートを GET /view で読み直すのはOCR再実行ではなく無課金です。定額プランは月間スキャン数・シート数・ストレージを追加します。