Pythonによる請求書解析:REST API活用ガイド
Pythonを使って請求書から構造化データを抽出。シンプルなREST APIを呼び出し、あらゆる請求書画像からJSON形式の項目、明細、そして検証可能な座標情報を取得する手順を解説します。
請求書から構造化データを抽出するのは、よくある作業ですが、手間がかかりがちです。スキャンした領収書や取引先の請求書がJPEGやPNGで大量にあり、そこから請求書番号、合計金額、各明細項目を経理や分析のために抜き出す必要がある、といった状況です。多くのOCRツールはテキストの羅列を出力するだけで、結局は不安定な正規表現を駆使して構造を復元するしかありません。
もっと直接的な方法があります。それは、必要な構造化JSONを返すREST APIを呼び出すことです。このAPIを使えば、抽出された全ての値が、元の帳票上のどの位置にあるのかまで正確に追跡できます。以下のインタラクティブデモがその最終結果です。左側の項目をクリックすると、請求書上で該当箇所がハイライトされます。
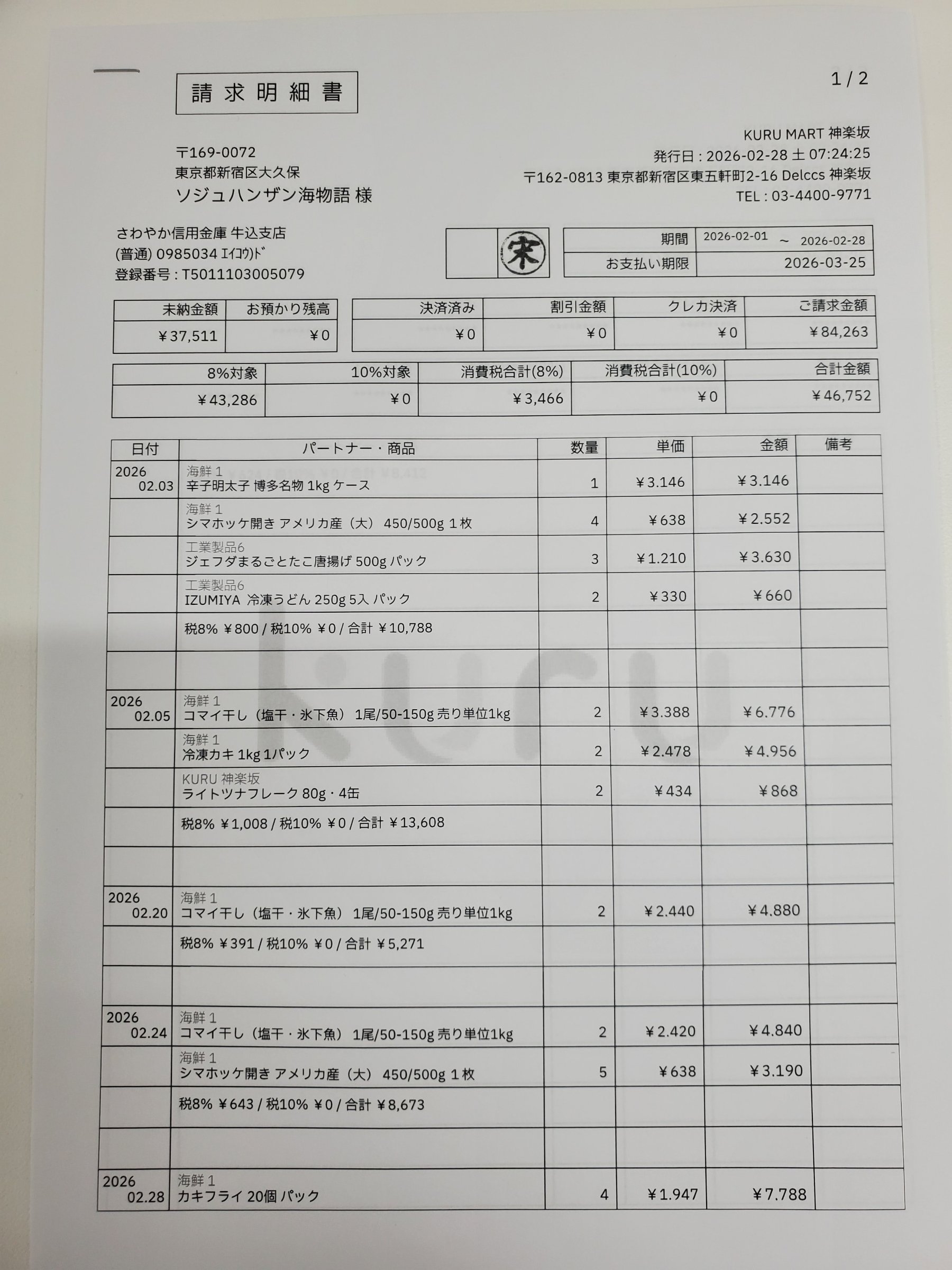
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
space-ocrはインストールするライブラリではなく、純粋なHTTPサービスです。手順はシンプルです。請求書画像をPOST /ocr/fieldsエンドポイントに送信し、取得したいデータのスキーマを定義するだけです。invoice_numberやtotal_dueといった項目や、品名と価格の列を持つline_itemsテーブルなどを指定できます。APIは、このスキーマに一致したクリーンなJSONオブジェクトを返します。
各項目のレスポンスには、"20250430-001"といったinvoice_numberのテキスト値だけでなく、その座標と信頼度スコアも含まれます。このmatch_ratioは、抽出されたテキストがページ上で見つかった文字とどれだけ一致したかを示し、データ品質の信頼できる指標となります。以下のPythonスクリプトで、この一連の流れをゼロから実装する方法を解説します。
import os
import base64
import requests
import json
# Get your API key from an environment variable
API_KEY = os.environ.get("SPACE_OCR_API_KEY")
IMAGE_PATH = "./path/to/your/invoice.jpg" # Path to your invoice image
API_URL = "https://api.space-ocr.com/ocr/fields"
if not API_KEY:
raise ValueError("API key not found. Set the SPACE_OCR_API_KEY environment variable.")
# Define the schema for the data you want to extract
# For line items, use type 'array' and define columns in 'children'
fields_schema = [
{"name": "supplier", "type": "string", "description": "The name of the company that issued the invoice."},
{"name": "invoice_number", "type": "string"},
{"name": "issue_date", "type": "date"},
{"name": "total_due", "type": "number"},
{
"name": "line_items",
"type": "array",
"description": "All items listed in the invoice table.",
"children": [
{"name": "item_description", "type": "string"},
{"name": "unit_price", "type": "number"},
{"name": "quantity", "type": "number"},
{"name": "line_total", "type": "number"}
]
}
]
# Read the image file and encode it in base64
with open(IMAGE_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"image": base64_image,
"imageType": "base64",
"fields": fields_schema
}
print(f"Sending request for {IMAGE_PATH}...")
response = requests.post(API_URL, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()['data']
print("\n--- Extracted Invoice Data ---")
for field_name, field_data in result.items():
if isinstance(field_data, list):
print(f"\n{field_name}:")
for i, row in enumerate(field_data):
print(f" - Item {i+1}:")
for col_name, col_data in row.items():
print(f" {col_name}: {col_data['value']} (Confidence: {col_data['match_ratio']:.2f})")
else:
print(f"{field_name}: {field_data['value']} (Confidence: {field_data['match_ratio']:.2f})")
# Bounding box is available at field_data['bbox']
# e.g., print(f" bbox: {field_data['bbox']}")
else:
print(f"Error: {response.status_code}")
print(response.text)space-ocrは、精度を保証するために、単に言語モデルの出力を鵜呑みにすることはありません。モデルはテキスト値に加え、ページ上のどの単語を使用したかのヒントを返します。次に、エンジンがその抽出値をページ上で実際にOCR認識された文字群と一文字ずつ照合します。このプロセスによって、信頼度スコアであるmatch_ratio(0.85以上で高信頼度と判断)と最終的なバウンディングボックスが生成されます。すべての座標(xmin, ymin, xmax, ymax)は0から1000の範囲に正規化されているため、元画像の解像度に依存しません。
APIの料金は、項目数やページの複雑さではなく、リクエストごとに課金されます。画像1枚あたり¥10で、結果の生成に失敗したリクエストは課金対象外です。新規アカウントには、毎月100回分の無料スキャンが付与されます。
- APIキーの取得space-ocrの無料アカウントにサインアップし、ダッシュボードの設定画面でAPIキーを確認します。キーは'spocr_'で始まります。
- 請求書画像の準備請求書をJPEGやPNGなどの一般的な画像ファイルとして保存します。スクリプトから参照できるよう、ファイルパスを控えておきます。
- データスキーマの定義Pythonスクリプト内で、抽出したい項目の名前と型を定義するJSON配列を作成します。明細テーブルもここで定義します。
- Pythonスクリプトの作成requestsライブラリを使い、画像を読み込んでbase64に変換し、AuthorizationヘッダーにAPIキーを設定してhttps://api.space-ocr.com/ocr/fieldsにPOSTするスクリプトを作成します。
- 実行とJSONの処理スクリプトを実行します。出力された構造化JSONレスポンスを、データベースや会計ソフト、分析ツールなどに取り込みます。