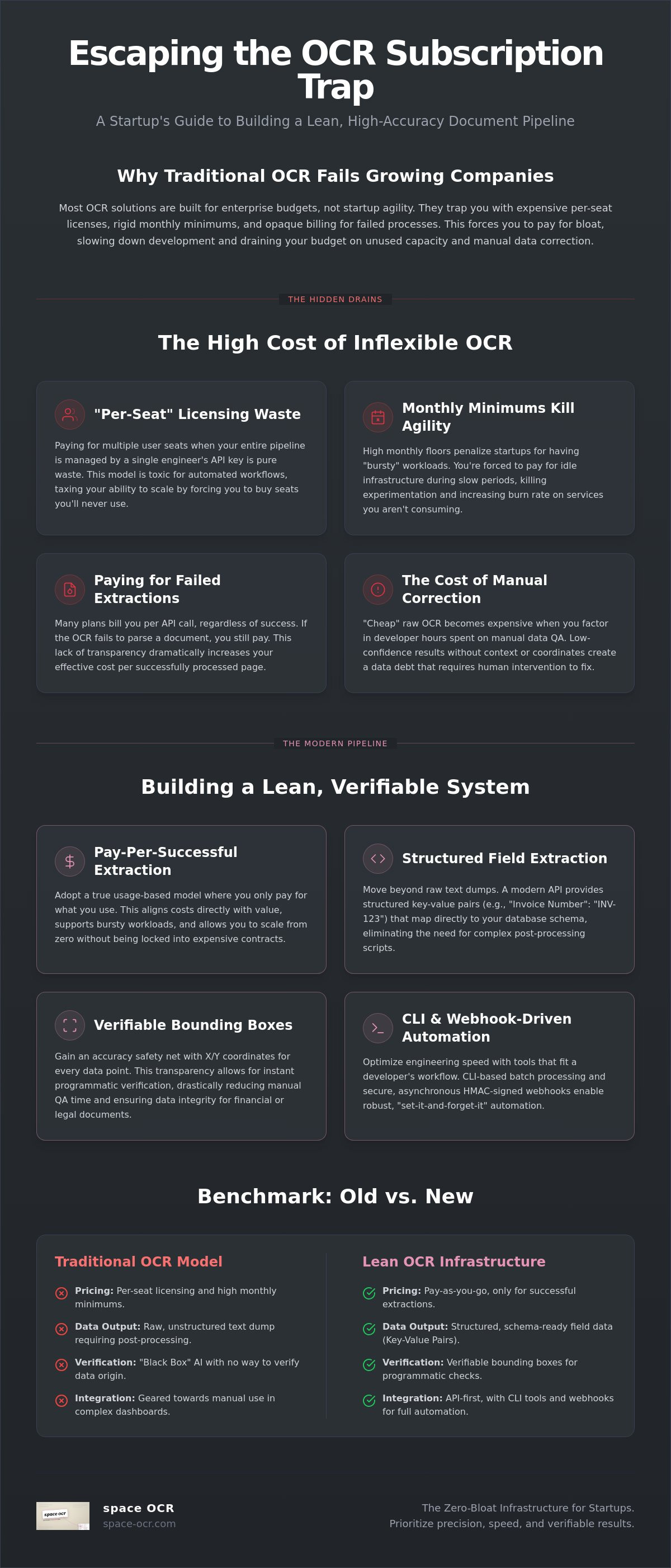
スタートアップ向け低コストOCR:ムダを削ぎ落とした書類処理の実践ガイド
スタートアップ向け低コストOCRの実践ガイド。従量課金、検証できるバウンディングボックス、CLIとAPIによる軽量ワークフローを、企業向けのムダなしで解説する。

最もコストが高い書類処理パイプラインは、1ページあたりの単価が最も高いものとは限らない。むしろ、使うことのない席(シート)にまで料金を払わされるパイプラインこそ、いちばん高くつく。多くの創業者は「無料」プランから始め、いざ規模を広げる段になって壁にぶつかる。一方で、実際の利用量を無視した企業向け契約に縛られてしまうケースもある。スタートアップに合った低コストOCRを見つけるには、マーケティングの装飾を取り払い、素の実用性だけを見る必要がある。予告なく跳ね上がるAPI請求の管理や、幻覚(ハルシネーション)で生成されたデータの手直しに、もう疲れている人も多いだろう。
エンジニアの時間は、手作業の検証や壊れやすい連携に費やすには貴重すぎる。必要なのは、予算とデータの整合性の両方を尊重する仕組みだ。本ガイドでは、企業向けサブスクリプションの負担を抱えずにスケールする書類処理パイプラインの作り方を示す。従量課金の考え方、バウンディングボックスによって検証できるデータ、そして開発環境にそのまま組み込めるCLIベースのワークフローを、順を追って分解していく。ムダな機能に払うのをやめ、精度と検証可能な結果を優先したパイプラインを組み始めよう。
要点
- 書類処理の予算を膨らませる「席課金」ライセンスや月額下限といった見えにくいコストを特定し、切り離す。
- 生のテキスト抽出と、構造化されたフィールドデータを区別し、検証済みで整合性の高い情報だけをデータベースに渡す。
- 成功した抽出にだけ料金を払う従量課金モデルを採用して、スタートアップ向けの低コストOCRを実装する。
- CLIベースのワークフローと、HMAC署名付きWebhookによる安全な非同期処理で、開発スピードを上げる。
- バウンディングボックスで座標を原本と照合して確認することで、手作業のQA時間を減らす。
目次
- サブスクの罠を超えて:なぜスタートアップはOCRに払いすぎるのか
- 低コストOCRを見極める:精度・速度・検証可能性
- 2026年のOCR料金モデルを読み解く
- ムダのない書類処理パイプラインを作る:連携戦略
- space-ocr:スタートアップのためのムダなしインフラ
サブスクの罠を超えて:なぜスタートアップはOCRに払いすぎるのか
スタートアップは、企業向けの高機能を業務効率と取り違えがちだ。従来型のベンダーの多くは、新しい会社の不安定な成長サイクルではなく、予測しやすい大企業の予算に合わせて料金を組んでいる。このズレが「サブスクの罠」を生む。成果ではなく可能性に対して料金を払わされる構図だ。スタートアップ向けの低コストOCRを探すというのは、表向きの最安値を追うことではない。使ってもいないインフラに払わせる、構造的なムダを避けることだ。膨らんだ月額下限を通じて、ベンダーの営業部門を養う必要などない。
「席課金」ライセンスは、技術的な書類ワークフローにとって特にたちが悪い。光学文字認識(OCR)のAPIを一人のエンジニアが回しているだけなのに、5席や10席の必須ユーザー枠に料金を払うのは純粋なムダだ。こうした席は、バッチ処理やWebhookといった上位機能を使うための前提条件になっていることが多く、実質的にスケールする力へ課税されている。この方式は、価値がデータのスループットにあってダッシュボードにログインした人数にはない、という現代の自動化の実態を無視している。
月額下限も同じ壁になる。実験の芽と方向転換のスピードを潰してしまう。書類の解析が必要な新機能を試そうとしているだけなのに、プロダクトマーケットフィットを検証する前から高い月額の下限で罰せられるのはおかしい。この「バースト的なワークロード」の問題は、多くの初期段階チームにとって現実だ。閑散期には眠り、マーケティング施策や季節的なスパイクが来たら即座にスケールする仕組みが必要になる。この柔軟性がなければ、使ってすらいないサービスのためにバーンレートだけが上がっていく。
定額制月額サブスクの問題点
定額プランは、予測しやすさという幻想を与えながら、実は硬直したスケール制約を隠している。ファイルサイズの上限や特定のエクスポート形式など、たった一つの機能の壁にぶつかったせいで、チームが早すぎる上位プランへ押し上げられることも多い。さらに、「成功」した抽出と「失敗」した抽出の扱いに透明性が欠けている点も見過ごせない。APIコールが書類の解析に失敗しても課金され続けるなら、1ページあたりの実効コストは上がっていく。本来はspace-ocrのWebアプリのように、差し込んですぐ使えるべきツールの導入に、こうした不要な摩擦が生まれてしまう。
書類AIにおける総保有コスト(TCO)
本当のコストはAPIの請求額だけではない。連携に費やす開発工数と、手作業でデータを直す手間も含まれる。OCRエンジンが座標のない低信頼データを返すと、チームは何時間も手作業のQAに追われる。検証できるバウンディングボックスを返す構造化フィールドOCR APIを使えば、この下流でのデータ清掃を減らせる。「安い」だけの生OCRは、二次的なAIレイヤーや人手の介入が必要な「データの負債」を引き継いだと気づいた瞬間、結局は高くつく。スタートアップ向けの低コストOCRを実装するとは、最初の呼び出しから構造化された検証可能な出力を返すツールを選ぶ、ということだ。
低コストOCRを見極める:精度・速度・検証可能性
精度は定数ではなく変数だ。データベース駆動のアプリを作る開発者にとって、生のテキスト文字列はしばしば負債になる。必要なのは、スキーマに直接マッピングできる構造化フィールド、つまりキーと値のペアだ。スタートアップ向けの低コストOCRがつまずくのは、まさにここだ。基本的なエンジンは文脈を無視してテキストを吐き出すだけなので、そのデータを使える形にするために複雑な正規表現や後処理スクリプトを書く羽目になる。データベースが「請求書番号」と「合計金額」を要求するなら、ただのテキストの塊では足りない。書類の構造を理解するエンジンが要る。
次の指標では遅延(レイテンシ)が効いてくる。ユーザーが結果を待っているリアルタイムのアプリで、長い処理待ちは許されない。グローバル前提のスタートアップなら多言語対応も考える必要がある。英語専用の書類では良い成績を出すエンジンでも、日本語・韓国語・中国語などの文字を処理すると失敗し、パイプラインの中で静かにデータが壊れていくことがある。space-ocrは書類の言語を自動で判定する。一つのエンジンが日本語・韓国語・中国語・英語のテキストを、言語パラメータもセレクタもなしに扱うので、対応言語の広さのために別の連携を組む必要はない。
検証可能なバウンディングボックス:精度のセーフティネット
バウンディングボックスは、抽出した各値がページ上のどこにあるかを示す。space-ocrは4つの整数 — xmin, ymin, xmax, ymax — を0〜1000の正規化グリッド上で返す。(0,0)が左上、(1000,1000)が右下だ。描画済み画像の上に枠を描くにはピクセルに戻して換算する。たとえば pixel_x = xmin / 1000 * image_width のようにする。各値にはmatch_ratioも付く。これはモデルの自己確信度ではなく、その値の文字のうち、ページのOCRで実際に検出されたシンボルの中からどれだけが実際に見つかったかの割合だ。0.85のしきい値を下回る値はすべて低信頼としてラベル付けされるので、それらだけをレビューに回せる。「ブラックボックス」を信じる代わりに、特定の値がページの正しい領域から取り出されたことをシステム側で確認できる。IBMによるOCRの解説を読むと、空間認識がデータの整合性にとっていかに根本的かがわかる。そのうえで、人手による確認(HITL)はmatch_ratioの低いフィールドだけに絞り込め、手作業のQAの負荷を削れる。
インフラ比較:クラウド大手 vs. 専用API
AWSやGoogleのようなクラウド事業者は、基本的なテキスト抽出なら1,000ページあたり約$1.50と、生のコストは低い。しかし構造化データを得るための実装は複雑だ。生の出力の上に解析ロジックを組むのは自分たちの責任になる。一方、企業向けプラットフォームは構造化出力を提供するものの、法外な月額下限を要求する。構造化フィールドOCR APIのような専用ツールは、その中間を埋める。スタートアップが求める従量課金の柔軟さを保ちながら、構造化抽出を提供する。おかげで、データの精度も開発時間も犠牲にせずに、スタートアップ向けの低コストOCR戦略をスケールさせられる。
2026年のOCR料金モデルを読み解く
2026年の料金戦略は、不透明な階層から、粒度の細かいイベント課金へと移ってきた。作り手にとって最も効果的なスタートアップ向け低コストOCRは、「失敗税」をなくすものだ。エラーを返したり、使える結果を出せなかった書類に払う理由はない。成功時のみ課金される1枚あたり¥10のようなモデルなら、バーンレートはベンダーのサーバー負荷ではなく、プロダクトの実際の実用性に直接ひもづく。ランウェイを尊重する、現実的なインフラの考え方だ。
リアルタイムの同期呼び出しはユーザー向けの検証に便利だが、それだけが選択肢であってはならない。Webhook付きのバッチ処理を使えば、緊急でない抽出を非同期キューに逃がせる。バッチを投げ、エンジンが順に処理し、各結果ができるたびにエンドポイントへ ocr.completed イベントが届く。これでインフラへの圧力が下がる。素早いプロトタイピングには、クレジットカード不要の無料枠も効く。space-ocrには毎月100回の無料スキャンが含まれるので、本番に1円もかける前に、エッジケースの検証やスキーマ互換性の確認ができる。課金サイクルに触れる前に、ツールの挙動を確かめられるわけだ。
従量課金OCRとは何か
このモデルは、課金を成功した抽出イベントに厳密にひもづける。あなたと提供者のインセンティブがそろう。複雑な表やぼやけたスキャンの解析にエンジンが失敗すれば料金は発生しない。失敗した呼び出しは自動で返金される。支出の見通しは、ユーザーの伸びの単純な関数になる。ユーザーあたりの平均書類数がわかっていれば、OCRコストはかなり正確に見積もれる。ページ数のしきい値を越えた瞬間に追加料金を求めてくる、サブスクにありがちな突然の「ティア上げ」ショックを避けられる。
「無制限」OCRプランの神話
「無制限」は技術的な実態ではなくマーケティング用語だ。この手のプランはたいてい、いちばん必要なときにスループットを抑える強めのスロットリングや「公平利用」ポリシーを隠している。まともなデータ設計に必要な、粒度の細かい監査ログを欠いていることも多い。透明で1枚単位の記録があれば、コンプライアンスやデバッグに必要な検証可能な証跡が手に入る。何が処理されたのか、そして各値をページ上の位置に固定する座標(バウンディングボックス)を、正確に確認できる。データをブラックボックスとして扱う定額プランには、この水準の詳細さがない。透明性こそが、スタートアップ向けの低コストOCRを規模が大きくなっても信頼できるものに保つ。
ムダのない書類処理パイプラインを作る:連携戦略
どのインターフェースを選ぶかが、運用スピードを決める。REST APIは本番システムの背骨だが、スタートアップ向けの低コストOCR戦略には、立場の異なる関係者のためにCLIとWebアプリのアクセスも含めておきたい。開発者は素早いテストとローカル自動化のためにターミナル向けのツールを欲しがり、運用チームは例外の管理やエッジケースの確認のためにGUIを欲しがる。手入力から自動解析へ移るには、こうした別々のワークフローを、余計なアーキテクチャの負担なしに扱えるパイプラインが要る。
自動化パイプラインでは、セキュリティを後回しにできない。HMAC署名付きWebhookなら、取り込みエンドポイントは提供者からの検証済みペイロードだけを処理する。space-ocrはすべての配信に X-Spaceocr-Signature ヘッダー(HMAC-SHA256)で署名する。これでなりすましを防ぎ、スケールしてもデータの整合性を守れる。Webhookによる非同期処理を使えば、OCRエンジンが裏側で重い仕事をこなしている間も、アプリは応答性を保てる。ocr.completed イベントを待ち受け、署名を検証し、構造化データをデータベースへ取り込む。サーバー側の待ち時間を最小化した、疎結合できれいなアーキテクチャだ。
space-ocrのWebアプリで書類を「Spaces」に整理すると、チームでの共同作業と整った形でのデータ保管がしやすくなる。プロジェクト・顧客・種類ごとに書類をまとめられるので、エクスポート前に抽出結果を監査しやすい。アプリ内ではシート横断のキーワード検索で任意の値を見つけ、キーボードでグリッドを移動できる。プログラムからアクセスするなら、GET /view APIが保存済みシートに対してサーバー側で where・sort・select のフィルタを実行し、OCRを再実行することも課金されることもない。技術者でないメンバーも、値とバウンディングボックスを見てエンジンがフィールドを正しく対応づけたかを確認できる。確認できたらCSVにエクスポートして、社内システムに流し込む。
手順:OCRをCLIに組み込む
Claude Code向けのspace-ocrプラグインを使えば、抽出をターミナルに持ち込める。インストールは2行だ。/plugin marketplace add oisidonut/claude-space-ocr-skill の次に /plugin install space-ocr@space-ocr を実行する。依存関係のないPythonクライアント経由でspace-ocr REST APIと通信する。pip installもSDKもMCPサーバーも要らない。そこから、書類の画像(請求書・領収書・名刺・身分証・帳票)をスキーマにマッピングされる構造化JSONに変換したり、すでにスキャンした書類に問い合わせたりできる。開発環境を離れる必要はない。初期段階の開発サイクルを鈍らせがちな、あのコンテキストスイッチがなくなる。
乱れたデータを扱う:領収書・請求書・手書き
低品質なFAXや手書きメモからの抽出は、一貫した正規化があると扱いやすくなる。space-ocrはデフォルトで値をそのまま保つ。カンマ・小数点・全角文字はページに現れたとおりに残る。一方で、フィールドの説明(description)を通じて、ISO 8601形式の日付や特定の通貨形式といった正規化された形をリクエストすることもできる。抽出の時点で正規化しておくと、下流の分析での静かな失敗を防げる。フィールドをバウンディングボックスとmatch_ratioのスコアに照らして確認したら、そのままデータベースへ取り込むためにエクスポートできる。これで、書類の品質にかかわらず、スタートアップ向けの低コストOCRパイプラインを信頼できる真実の源に保てる。なお、エンジンとAPIはラスター画像(JPEG、PNG、GIF、BMP、TIFF、WebP)を受け取る。複数ページのPDFをWebアプリにドロップすると、各ページをPNGにラスタライズしてからOCRを実行する。
構造化フィールドOCR APIをスタックに組み込んで、自動化ワークフローの構築を今日から始めよう。
space-ocr:スタートアップのためのムダなしインフラ
space-ocrは、VC出資のプラットフォームが好む肥大した機能よりも、素の実用性を優先する。創業者にとって、スタートアップ向けの低コストOCR探しは、失敗した呼び出しに払うのをやめた瞬間に終わる。1枚あたり¥10のモデルなら、資本は実際に使えるデータに費やされる。エンジンが有効な結果を返さなければ、残高は減らない。このインセンティブの一致こそ、マーケティングの約束より精度を重んじる人のために作られた「ムダなしインフラ」の土台だ。
本番では精度に妥協は許されない。space-ocrは抽出したフィールドごとに検証可能なバウンディングボックスを返すので、各値のページ上の出所をシステムで確認できる。テキスト検出にはGoogle Cloud Vision、構造化にはGoogle Geminiを使うが、モデルが座標を発明することはない。エンジンは抽出した各値を、ページの実際のOCRシンボルと文字単位で照合し、match_ratioでスコアリングする。だから、どのフィールドも盲目的に信じるのではなく検証される。日本語・韓国語・中国語・英語を一つのエンジンで自動言語判定できるので、パイプラインはグローバルな野心とともにスケールする。企業向け契約なしで、対応言語の広さが手に入る。開発者ファーストの表面には、Claude Code向けのspace-ocrプラグインと、構造化フィールドOCR APIの完全なドキュメントが含まれるので、読む時間を減らして出荷する時間を増やせる。
なぜ初期段階のチームにspace-ocrが向くのか
初期段階のチームは、調達に足を取られずに速く動く必要がある。方向転換のスピードを鈍らせる席課金ライセンスも、隠れたプラットフォーム料金もない。アプリ内ではシート横断のキーワード検索で任意の抽出値を見つけられる。プログラムからアクセスするなら、GET /view APIが保存済みデータに対してサーバー側で where・sort・select のフィルタを実行する。過去データを抱えている場合は、非同期の /upload とWebhookを組み合わせれば、リクエストを開いたまま待たせずに書類のバックログを片付けられる。利用が伸びたときだけ育つインフラだ。遊んでいる容量や使わない席には払わず、アプリを動かすデータにだけ払う。
数週間ではなく数分で始められる
新しい書類パイプラインを試すのに、営業への電話やクレジットカードは要らないはずだ。無料枠で抽出を試せる。毎月100回のスキャンで、自分の書類セットに対して精度を確認できる。最初のWebhookの設定は数分で済み、複雑なミドルウェアなしで既存スタックへの安全なデータ取り込みを有効にできる。ローカルのワークフローにClaude Code向けのspace-ocrプラグインを使うにせよ、手作業での確認にspace-ocrのWebアプリを使うにせよ、連携は軽いままだ。書類処理に払いすぎるのをやめ、現代のスタートアップのスタックのために設計された高精度エンジンの上に構築を始めよう。
サブスクではなく精度でパイプラインを作る
スタートアップに、使わない席や失敗したAPIコールに資本をムダにする余裕はない。従来の料金モデルや硬直したサブスクが、開発パイプラインにどれだけ不要な摩擦を生むかを見てきた。構造化フィールドの抽出と検証可能なデータに集中すれば、費やす1円すべてがプロダクトの信頼性に直結する。スタートアップ向けの低コストOCRを実装するとは、アーキテクチャの透明性と利用量に応じたスケーリングのことだ。企業向け契約のオーバーヘッドなしに精度を提供する仕組みが要る。
space-ocrはそれを、1枚あたり¥10のモデルと、全フィールドの検証可能なバウンディングボックスで実現する。速度を鈍らせる隠れた料金も月額下限もなく、毎月100回のスキャンが無料だ。書類パイプラインの精度をすぐに検証でき、自分のユースケースをテストし始めるのにクレジットカードは要らない。マーケティングの装飾よりも素の実用性と技術的な誠実さを重んじるチームのための、現実的な解だ。
space-ocrでデータ抽出を無料で始めよう。エンジニアの時間と予算の両方を尊重する書類パイプラインを作ろう。データには精度を、ランウェイには敬意を。さあ、良いものを作りに行こう。