Parse Invoices in Python: A REST API Guide
Extract structured data from invoices using Python. A guide to calling a simple REST API to get JSON fields, line items, and verifiable coordinates for any invoice image.
Getting structured data from invoices is a common but frustrating task. You might have a folder of scanned receipts or vendor invoices as JPEGs or PNGs, and you need to pull out the invoice number, total amount, and each line item for accounting or analysis. Most OCR tools dump a wall of text, leaving you to piece the structure back together with fragile regular expressions.
There is a more direct way: a REST API call that returns the structured JSON you need, with every value traced back to its exact location on the page. The interactive demo below shows the final result. Click any field on the left to see its position highlighted on the invoice.
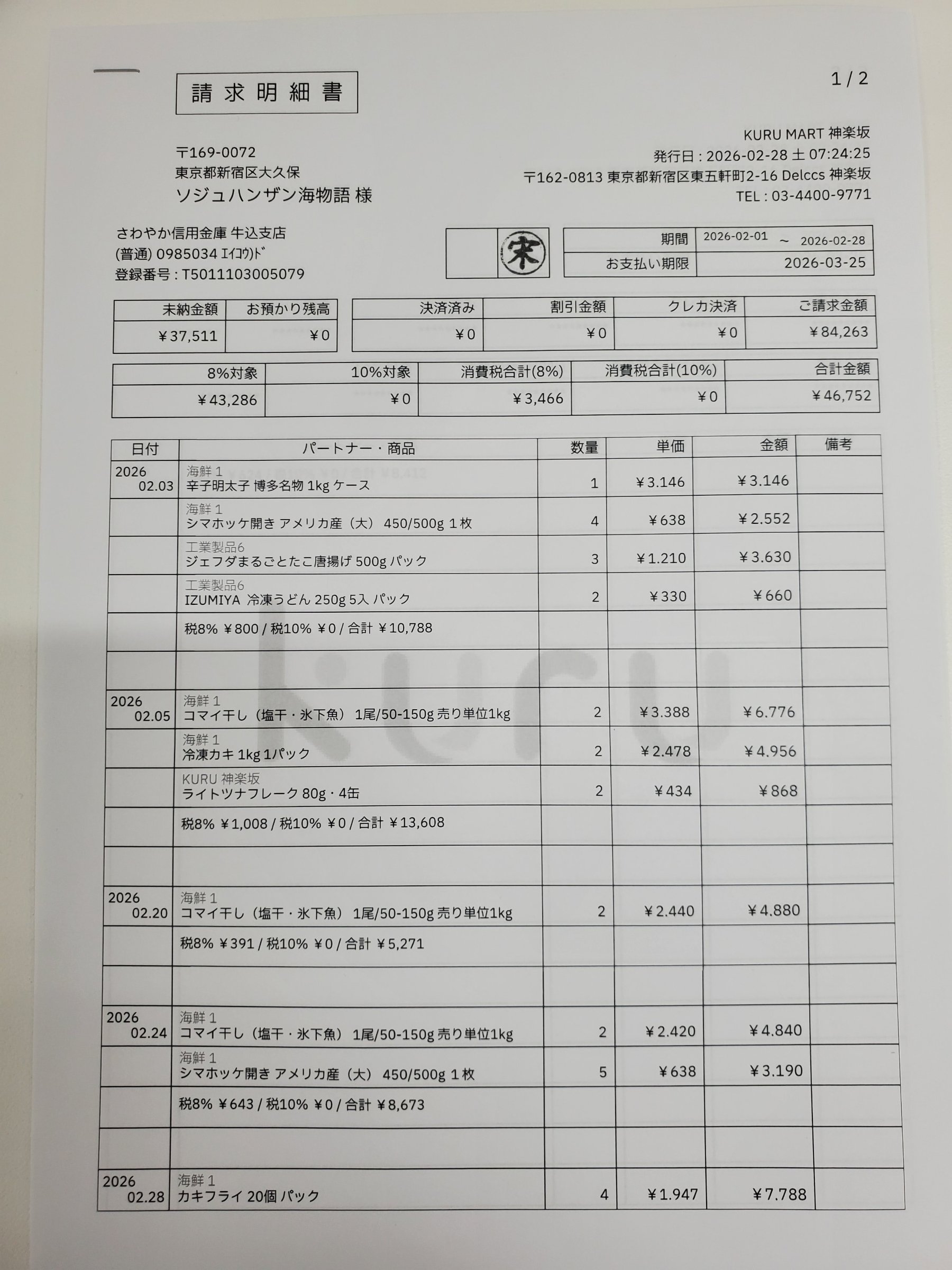
Each value with a box carries a verified on-page location — bbox + 4-point vertices + match_ratio — on a 0–1000 normalized grid (0,0 top-left → 1000,1000 bottom-right), the same shape the live API returns. Hover a field to trace it back to the pixels it came from.
space-ocr is not a library you install, but a plain HTTP service. The process is simple: take an invoice image, send it to the POST /ocr/fields endpoint, and define the schema you want back. You can specify fields like invoice_number, total_due, and a table of line_items with columns for description and price. The API returns a clean JSON object matching your schema.
The response for each field includes not just the text value, like an invoice_number of "20250430-001", but also its coordinates and a confidence score. This match_ratio tells you how well the extracted text aligned with the characters found on the page, giving you a reliable signal for data quality. The Python script below shows how to do this from scratch.
import os
import base64
import requests
import json
# Get your API key from an environment variable
API_KEY = os.environ.get("SPACE_OCR_API_KEY")
IMAGE_PATH = "./path/to/your/invoice.jpg" # Path to your invoice image
API_URL = "https://api.space-ocr.com/ocr/fields"
if not API_KEY:
raise ValueError("API key not found. Set the SPACE_OCR_API_KEY environment variable.")
# Define the schema for the data you want to extract
# For line items, use type 'array' and define columns in 'children'
fields_schema = [
{"name": "supplier", "type": "string", "description": "The name of the company that issued the invoice."},
{"name": "invoice_number", "type": "string"},
{"name": "issue_date", "type": "date"},
{"name": "total_due", "type": "number"},
{
"name": "line_items",
"type": "array",
"description": "All items listed in the invoice table.",
"children": [
{"name": "item_description", "type": "string"},
{"name": "unit_price", "type": "number"},
{"name": "quantity", "type": "number"},
{"name": "line_total", "type": "number"}
]
}
]
# Read the image file and encode it in base64
with open(IMAGE_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"image": base64_image,
"imageType": "base64",
"fields": fields_schema
}
print(f"Sending request for {IMAGE_PATH}...")
response = requests.post(API_URL, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()['data']
print("\n--- Extracted Invoice Data ---")
for field_name, field_data in result.items():
if isinstance(field_data, list):
print(f"\n{field_name}:")
for i, row in enumerate(field_data):
print(f" - Item {i+1}:")
for col_name, col_data in row.items():
print(f" {col_name}: {col_data['value']} (Confidence: {col_data['match_ratio']:.2f})")
else:
print(f"{field_name}: {field_data['value']} (Confidence: {field_data['match_ratio']:.2f})")
# Bounding box is available at field_data['bbox']
# e.g., print(f" bbox: {field_data['bbox']}")
else:
print(f"Error: {response.status_code}")
print(response.text)To ensure accuracy, space-ocr doesn't just trust the language model's output. The model returns the text value plus hints about which words it used on the page. The engine then performs a character-by-character match of the extracted value against the page's actual OCR symbols. This process generates the match_ratio confidence score (where ≥ 0.85 is a high-confidence match) and the final bounding box. All coordinates (xmin, ymin, xmax, ymax) are normalized to a 0-1000 scale, making them independent of the original image resolution.
The API is priced per call, not per field or page complexity. It costs $0.05 per image, and requests that fail to produce a result are not charged. New accounts get 100 free scans each month to start.
- Get Your API KeySign up for a free space-ocr account and find your API key in the dashboard settings. The key will start with 'spocr_'.
- Prepare Your Invoice ImageSave your invoice as a common image file, such as a JPEG or PNG. Note the file path for your script.
- Define Your Data SchemaCreate a JSON array in your Python script that defines the names and types of the fields you want to extract, including any line-item tables.
- Write the Python ScriptUsing the requests library, write a script to read the image, convert it to base64, and POST it to https://api.space-ocr.com/ocr/fields with your API key in the Authorization header.
- Run and Process the JSONExecute your script. It will print the structured JSON response, which you can then load into your database, accounting software, or analytics tool.
Do I need to install an SDK or library?
Can I process PDF invoices?
What are the coordinates in the response?
How do I handle line items or tables?
What if I don't know the invoice layout beforehand?
What does the match_ratio score mean?
Start parsing invoices in minutes.
Get your API key and 100 free scans a month. No credit card required.